들어가기 앞서
Amazon RDS for PostgreSQL는 소스 PostgreSQL 인스턴스의 복제본을 쉽게 구성하여 읽기 부하를 분산하고 재해 복구(DR) 리소스를 생성할 수 있게 해줍니다. 동일한 리전 내에서 또는 다른 리전에서 읽기 복제본을 구성할 수 있습니다. RDS PostgreSQL 읽기 복제본 인스턴스를 사용하면 읽기 작업 부하를 복제본 인스턴스로 오프로드하고 소스 인스턴스의 컴퓨팅 리소스를 쓰기 활동을 위해 예약할 수 있습니다. 그러나 읽기 복제본을 적절하게 구성하고 복제 지연을 방지하려면 적절한 매개변수 값을 설정해야 합니다.
개요
이 글에서는 읽기 복제본을 적절히 구성하기 위한 몇 가지 모범 사례를 제공하며, 여러 가지 RDS PostgreSQL 복제 옵션(내부 리전, 교차 리전, 논리적 복제)의 장단점을 논의합니다. 적절한 매개변수 값과 모니터링할 지표를 추천합니다. 다음 단계에서는 재해 복구 전략, 읽기 작업 부하 및 건강한 소스 인스턴스를 최적화하면서 복제 지연을 최소화하는 방법을 설명합니다.
일반적인 권장 사항
전체적인 모범 사례로, 읽기 복제본에서 실행하는 읽기 쿼리가 소스 인스턴스와 동일한 최신 데이터를 사용하도록 해야 합니다. 데이터 버전은 Amazon CloudWatch 지표에서 복제 지연을 확인하여 확인할 수 있습니다. 복제 지연을 최소화하면 오래된 데이터를 기반으로 한 쿼리 출력 및 소스 인스턴스의 건강 상태를 방지할 수 있습니다.
리전 내 복제
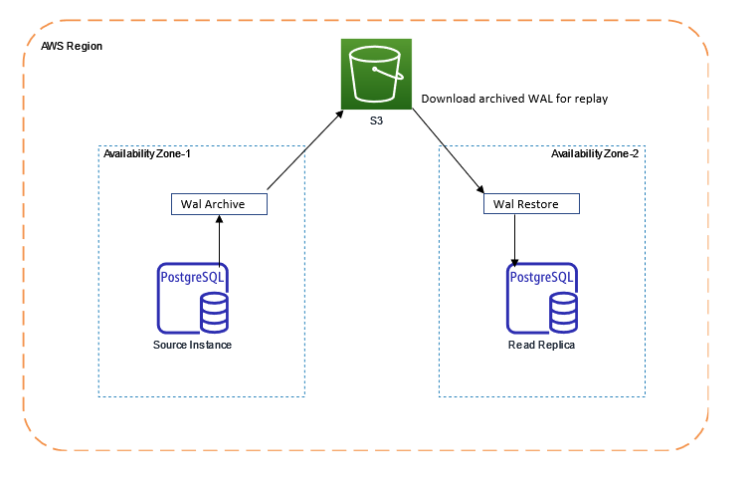
소스 인스턴스와 동일한 AWS 리전에서 읽기 복제본을 생성하려면 RDS PostgreSQL은 Postgres의 기본 스트리밍 복제를 사용합니다. 소스 인스턴스에서 데이터 변경 사항이 스트리밍 복제를 통해 읽기 복제본으로 전송됩니다. 이 과정이 지연되면 복제 지연이 발생합니다. 다음 다이어그램은 RDS PostgreSQL이 동일한 리전 내에서 소스와 복제본 간에 복제를 수행하는 방법을 설명합니다.
wal_keep_size의 적정 값
PostgreSQL에서 wal_keep_size는 pg_wal 디렉토리에서 유지되는 과거 로그 파일 세그먼트의 최소 크기를 지정합니다. RDS PostgreSQL은 이 매개변수를 초과하는 WAL 세그먼트를 Amazon S3 버킷으로 아카이브합니다. 읽기 복제본이 pg_wal 위치에서 WAL 세그먼트를 찾지 못하면, 읽기 복제본은 S3 버킷에서 세그먼트를 다운로드하고 복원하여 적용합니다. 일반적으로 아카이브에서 복원하는 과정은 스트리밍 복제보다 느리므로, 인스턴스에서 더 많은 WAL 세그먼트를 유지할수록 복제 속도가 빨라집니다.
스트리밍 복제가 중지되면 데이터베이스 로그에 다음과 같은 오류 메시지가 표시됩니다: Streaming replication has stopped. 만약 스트리밍 복제가 더 오랜 시간 동안 중지되면 다음과 같은 메시지가 나타날 수 있습니다: Streaming replication has been terminated.
기본적으로 RDS PostgreSQL은 wal_keep_size를 2GB로 설정합니다. 이 매개변수의 값을 RDS Parameter Group을 사용하여 수정할 수 있습니다. 이 매개변수는 동적이며 값을 변경해도 인스턴스가 재시작되지 않습니다.
예를 들어, 다음은 RDS가 읽기 복제본을 복구하는 동안 아카이브된 WAL 파일을 재생하는 Postgres 로그 메시지입니다:
2018-11-07 21:01:16 UTC::@:[23180]:LOG: restored log file "000000010000001A000000D3" from archive
RDS가 복제본에서 아카이브된 충분한 WAL 파일을 재생하여 동기화한 후, 읽기 복제본은 스트리밍을 다시 시작합니다. 이 시점에서 RDS는 로그 파일에 다음과 비슷한 내용을 기록합니다:
2018-11-07 21:41:36 UTC::@:[24714]:LOG: started streaming WAL from primary at 1B/B6000000 on timeline 1
모범 사례로, pg_wal 디렉토리의 최대 크기를 초과하지 않도록 하여 S3 버킷에서 세그먼트를 복원하는 느린 과정을 방지해야 합니다. 이 값을 조정하려면 소스 인스턴스에서 wal_keep_size 값을 변경하십시오. 새 복제본 인스턴스를 시작하기 전에 wal_keep_size 값을 변경하십시오. 이 매개변수를 충분히 높게 설정하여 스트리밍 복제가 시작될 때 WAL 파일이 아카이브되지 않도록 해야 합니다. 예를 들어 wal_keep_size를 10GB로 설정하면 소스 인스턴스에서 약 625개의 WAL 파일을 유지할 수 있습니다.
소스 인스턴스에서 과도한 쓰기 활동 피하기
소스 인스턴스에서는 쓰기 활동의 일환으로 WAL이 먼저 트랜잭션을 기록한 후, 변경 사항을 스토리지 블록에 기록합니다. 소스 인스턴스에서 높은 쓰기 활동은 많은 WAL 파일을 생성할 수 있습니다. 이 WAL 파일의 수가 많아지고 읽기 복제본에서 재생되는 데 시간이 걸리면 복제 성능이 저하됩니다.
WAL 파일 생성 속도를 추적하려면 CloudWatch에서 TransactionLogsGeneration 지표를 확인하세요. 이 매개변수는 초당 생성되는 트랜잭션 로그의 크기를 보여줍니다.
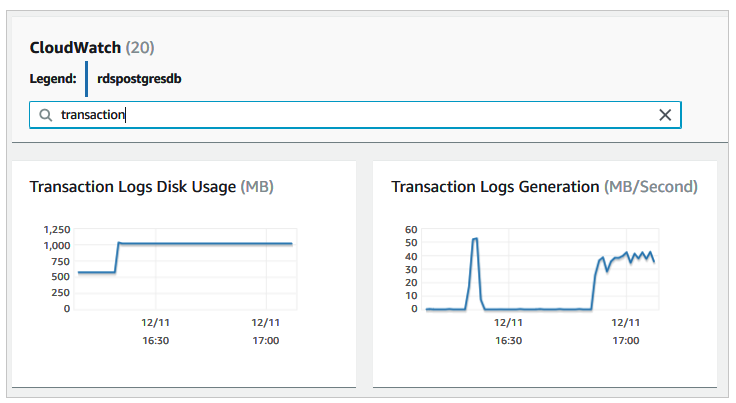
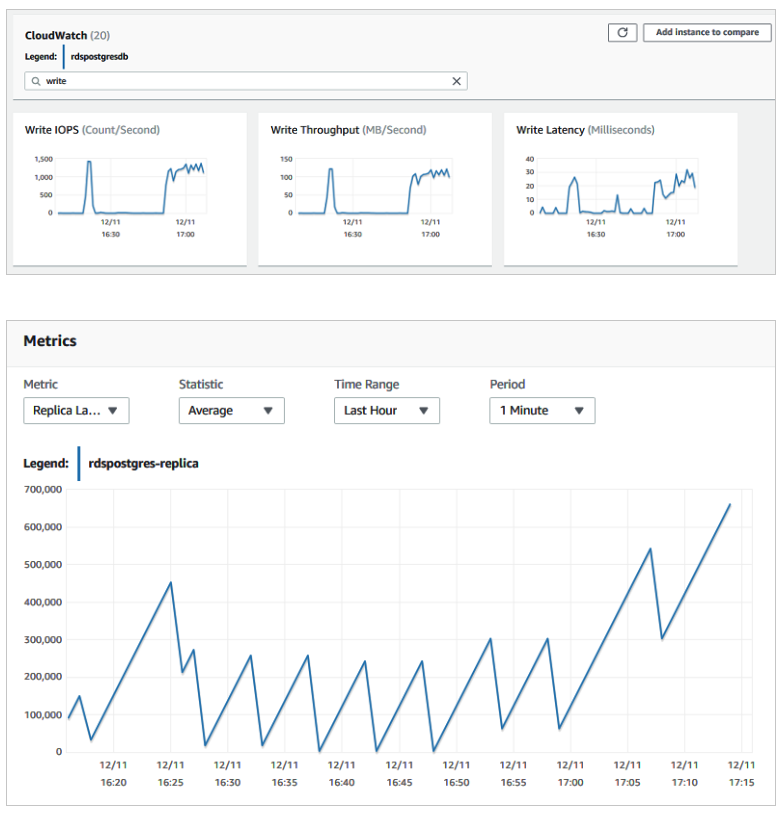
Write Latency와 Write IOPS와 같은 지표에서 CloudWatch 알림을 사용하여 소스 인스턴스에서 과도한 쓰기를 모니터링해야 합니다. wal_compression을 ON으로 설정하여 WAL의 양을 줄이고, 시간이 지나면서 복제 지연을 줄여야 합니다.
소스 인스턴스 테이블에서 독점 잠금 피하기
소스 인스턴스에서 DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL, REFRESH MATERIALIZED VIEW (CONCURRENTLY 없이)와 같은 명령을 실행하면, PostgreSQL은 Access Exclusive 잠금을 처리합니다.
ACCESS EXCLUSIVE는 가장 제한적인 잠금 모드로, 다른 모든 잠금 모드와 충돌하며 해당 테이블에 대한 다른 모든 트랜잭션의 접근을 막습니다. 일반적으로 테이블은 트랜잭션이 끝날 때까지 잠겨 있습니다. 이 잠금 활동은 WAL에 기록되고, 읽기 복제본에서 재생되며 유지됩니다. 테이블이 ACCESS EXCLUSIVE 잠금 상태로 오래 유지될수록 복제 지연이 길어집니다.
이러한 상황을 피하려면 AWS는 pg_locks와 pg_stat_activity 카탈로그 테이블을 주기적으로 쿼리하여 이 상황을 모니터링할 것을 권장합니다. 예를 들어, PostgreSQL 9.6 및 최신 버전에서 잠금을 모니터링하는 쿼리는 다음과 같습니다:
SELECT pid,
usename,
pg_blocking_pids(pid) AS blocked_by,
QUERY AS blocked_query
FROM pg_stat_activity
WHERE cardinality(pg_blocking_pids(pid)) > 0;읽기 복제본에서의 매개변수 설정
복제본 인스턴스에서 매개변수를 설정하여 전체 복제 성능에 영향을 미칠 수도 있습니다. 예를 들어, hot_standby_feedback 매개변수는 읽기 복제본에서 현재 실행 중인 쿼리에 대한 피드백을 소스 인스턴스로 보내는지 여부를 설정합니다. 이 매개변수를 활성화하면 소스에서 다음과 같은 오류 메시지가 나타나며, 읽기 복제본에서 쿼리가 완료될 때까지 VACUUM을 연기할 수 있습니다.
ERROR: canceling statement due to conflict with recovery
Detail: User query might have needed to see row versions that must be removed
이렇게 하면 hot_standby_feedback을 활성화한 읽기 복제본이 장기 실행 SQL을 처리할 수 있지만, 소스 인스턴스에서 테이블이 부풀어 오를 수 있습니다. 읽기 복제본에서 장기 실행 쿼리를 모니터링하지 않으면 소스 인스턴스에서 심각한 문제가 발생할 수 있습니다.
대안으로, 복제본 인스턴스에서 max_standby_archive_delay나 max_standby_streaming_delay와 같은 매개변수를 활성화하여 장기 실행 읽기 쿼리가 완료되도록 할 수 있습니다. 이 두 매개변수는 읽기 쿼리가 실행 중일 때 소스 데이터가 변경되면 복제본에서 WAL 재생을 일시 중지합니다. 값이 -1이면 읽기 쿼리가 완료될 때까지 WAL 재생이 기다립니다. 그러나 이 일시 중지는 복제 지연을 무기한 증가시키며, 소스에서 WAL 축적 때문에 높은 스토리지 소비를 일으킬 수 있습니다.
이 세 가지 매개변수를 변경하면 복제본 인스턴스에서 장기 실행 읽기 쿼리를 모니터링하여 소스 인스턴스의 건강을 유지하고 복제 지연을 관리할 수 있습니다.
읽기 복제본 인스턴스 구성
잘못된 복제본 인스턴스 구성도 복제 성능에 영향을 미칠 수 있습니다. 소스 인스턴스와 동일하거나 더 높은 인스턴스 클래스 및 스토리지 유형을 사용하십시오. 복제본이 소스 인스턴스와 동일한 쓰기 작업을 재생하고 추가적인 읽기 쿼리를 처리해야 하므로, 더 낮은 인스턴스 클래스를 사용하면 읽기 복제본에서 높은 지연이 발생하고 복제 지연이 증가할 수 있습니다.
읽기 복제본은 소스 인스턴스와 유사한 쓰기 작업 부하와 추가적인 읽기 쿼리를 처리합니다. 따라서 최소한 동일하거나 더 높은 인스턴스 클래스를 사용하는 것이 좋습니다. 마찬가지로 소스 인스턴스와 복제본 인스턴스의 스토리지 유형도 일치시켜야 합니다. 스토리지 구성이 일치하지 않으면 복제 지연이 증가합니다.
교차 리전 복제
RDS PostgreSQL은 교차 리전 복제도 지원합니다. 읽기 쿼리 확장 외에도 교차 리전 읽기 복제본은 AWS 리전 간의 재해 복구 및 데이터베이스 마이그레이션을 위한 솔루션을 제공합니다.
wal_keep_size를 기준으로 WAL 보존을 유지하는 대신, 교차 리전 복제는 소스 인스턴스에서 물리적 복제 슬롯을 사용합니다. CloudWatch 지표인 OldestReplicationSlotLag는 WAL 크기(MB)로 복제 지연을 보여줍니다. TransactionLogsDiskUsage는 WAL 파일이 사용하는 스토리지 크기를 나타냅니다. 복제 슬롯이 WAL을 유지하기 때문에 교차 리전 복제 지연은 소스 인스턴스에서 WAL이 축적되며, 결국 심각한 문제를 일으킬 수 있습니다.
모범 사례로, 소스 인스턴스에서 IOPS 성능도 모니터링해야 합니다. 즉, 소스 인스턴스가 IOPS 부족으로 인해 고지연이 발생하면 WAL 파일 읽기가 지연되어 교차 리전 복제 지연이 증가할 수 있습니다. 교차 리전 복제는 지리적으로 더 긴 거리가 관련되므로, 교차 리전 복제 지연을 면밀히 모니터링하여 소스 인스턴스에서 WAL 보존으로 인한 높은 스토리지 소비를 방지하는 것이 좋습니다.
논리적 복제
1. 논리적 복제란 무엇인가?
논리적 복제는 데이터베이스의 일부분 (예: 특정 테이블, 데이터베이스 등)을 복제하는 방식입니다. 이는 물리적 복제(전체 데이터베이스와 모든 데이터의 복제)와 달리, 선택적으로 특정 데이터만 복제할 수 있다는 장점이 있습니다.
예를 들어, 두 PostgreSQL 인스턴스에서 테이블 수준에서 복제할 수 있고, 복제할 데이터를 선택적으로 설정할 수 있습니다. 이 방법을 사용하면 여러 버전의 PostgreSQL을 복제하거나, 여러 데이터베이스를 하나로 통합할 수 있습니다.
- 물리적 복제는 데이터베이스 전체를 복제하는 방식으로, WAL 파일을 그대로 복제합니다. 즉, 원본 데이터베이스에서 발생한 모든 변경사항이 WAL 파일에 기록되고, 이 파일을 읽어 복제본에 그대로 반영하는 방식입니다.
- 반면, 논리적 복제는 테이블 수준이나 데이터베이스 수준에서 변경 사항만 복제하기 때문에, 전체 WAL 파일을 복제하는 것이 아니라, WAL에 기록된 특정 데이터 변경만을 처리합니다.
논리적 복제는 논리 복제 슬롯(logical replication slots)을 사용하여 WAL에서 특정 데이터 변경 사항만을 추출합니다. 이 방식으로 복제는 WAL 파일의 일부만을 사용하여 필요한 데이터만 복제합니다. 즉, 논리적 복제는 WAL 파일을 기반으로 변경 사항을 추적하고, 이를 복제본에 적용하는 방식입니다.
2. AWS DMS (Database Migration Service)와의 관계
AWS DMS는 데이터베이스 마이그레이션을 지원하는 서비스로, 논리적 복제의 가장 일반적인 사용 사례입니다. 즉, AWS DMS는 RDS PostgreSQL의 논리적 복제를 활용하여 데이터를 이동하거나 복제할 수 있습니다.
3. 논리적 복제 슬롯
- 복제 슬롯은 데이터베이스의 복제 상태를 관리하는 PostgreSQL의 기능입니다. 복제 슬롯은 WAL(Write Ahead Log) 파일을 관리하여 복제된 데이터를 추적합니다.
- 논리적 복제 슬롯은 물리적 복제 슬롯과 달리, 복제하는 데이터의 일부만을 다룹니다.
4. 문제점과 주의 사항
논리적 복제를 사용할 때 다음과 같은 문제가 발생할 수 있습니다:
- 소스 인스턴스의 스토리지가 빠르게 차는 문제: 복제 슬롯이 WAL 파일을 계속해서 축적하지만, 실제로 데이터를 소비하지 않으면 스토리지가 가득 차게 됩니다. 이를 방지하려면 복제 슬롯을 모니터링하고, 비활성 슬롯을 삭제해야 합니다.
- 스키마 변경: 논리적 복제에서는 스키마 변경이 제대로 적용되도록, 구독자(데이터를 받는 쪽)가 먼저 변경을 커밋하고, 게시자(데이터를 보내는 쪽)가 그 후에 커밋해야 합니다.
- 시퀀스 데이터: 논리적 복제는 시리얼(자동 증가) 또는 아이덴티티(고유 식별자) 열의 시퀀스 값을 복제합니다. 그러나 복제 중 장애가 발생하거나 장애 조치가 이루어지면, 시퀀스를 최신 값으로 업데이트해야 합니다.
- TRUNCATE와 DELETE: TRUNCATE는 테이블을 비우는 명령이지만, 논리적 복제에서 TRUNCATE 작업은 예기치 않게 처리될 수 있습니다. 대신 DELETE 명령을 사용하는 것이 안전합니다.
- 파티션 테이블: 논리적 복제는 파티션 테이블을 일반 테이블처럼 처리합니다. 파티션 테이블을 복제하려면 하나씩 복제해야 합니다.
- 외부 테이블: 논리적 복제는 외부 테이블(Foreign Table)은 복제하지 않습니다.
5. 복제 슬롯 관리
- 비활성 복제 슬롯을 찾아서 삭제하는 것이 중요합니다. 활성 상태가 아닌 복제 슬롯은 계속해서 WAL 파일을 소비하지 않기 때문에 스토리지가 가득 차는 문제를 발생시킬 수 있습니다.
- 이 모든 과정은 논리적 복제를 통해 데이터를 더욱 세밀하게 관리하고, 오류를 방지하기 위해 중요한 작업입니다.
'Database > postgreSQL' 카테고리의 다른 글
| AWS PostgreSQL 05 - 쿼리 충돌 처리하기 (1) | 2025.01.14 |
|---|---|
| AWS PostgreSQL 04 - Physical Replication (0) | 2025.01.13 |
| AWS PostgreSQL 02 - VACUUM (0) | 2025.01.13 |
| AWS PostgreSQL 01 - MVCC (4) | 2025.01.13 |