Horizontal Pod Autoscaling
Kubernetes에서 HorizontalPodAutoscaler(HPA)는 Deployment나 StatefulSet 같은 워크로드 리소스를 자동으로 업데이트하여, 수요에 따라 파드 수를 자동으로 조절한다. 수평 스케일링(horizontal scaling)은 부하 증가 시 파드 수를 늘려 대응하는 방식이다. 이는 수직 스케일링(vertical scaling)과는 다른 개념으로, 수직 스케일링은 기존 파드에 CPU나 메모리 같은 리소스를 더 많이 할당하는 방식이다. 부하가 줄어들고 파드 수가 설정된 최소값보다 많으면, HPA는 워크로드 리소스에 스케일 다운을 지시하여 파드 수를 줄인다. 단, HPA는 DaemonSet처럼 스케일이 불가능한 오브젝트에는 적용되지 않는다.
구성 요소
HPA는 Kubernetes의 API 리소스와 컨트롤러로 구성된다.
- API 리소스는 HPA의 동작 방식을 정의한다.
- 컨트롤러는 Kubernetes 컨트롤 플레인에서 실행되며, 주기적으로 타겟 워크로드(예: Deployment)의 원하는 파드 수를 조정한다.
컨트롤러는 다음과 같은 메트릭을 기준으로 동작한다:
- 평균 CPU 사용률
- 평균 메모리 사용률
- 사용자가 정의한 커스텀 메트릭
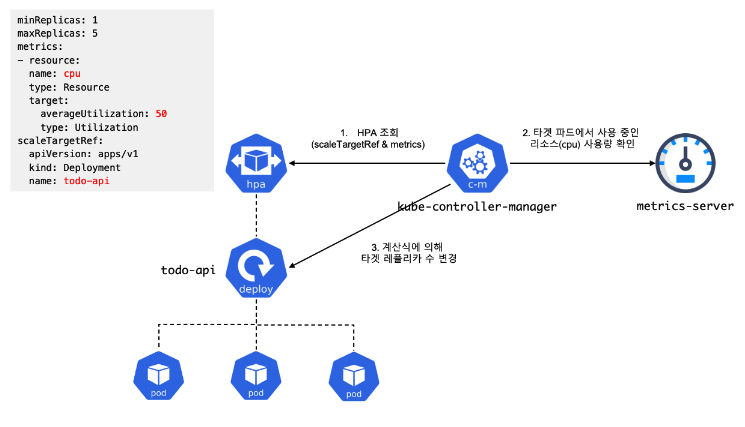
HorizontalPodAutoscaler는 어떻게 동작하는가?
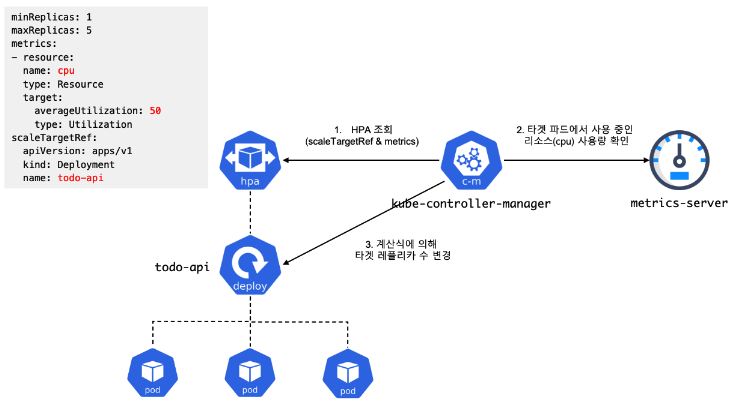
Kubernetes는 HorizontalPodAutoscaler(HPA)를 컨트롤 루프(control loop) 형태로 구현한다. 이 루프는 지속적으로 실행되지 않고 일정 주기로 실행된다. 이 주기는 kube-controller-manager의 --horizontal-pod-autoscaler-sync-period 플래그로 설정되며, 기본값은 15초이다.
동작 흐름
HPA가 주기적으로 수행하는 주요 단계는 다음과 같다.
- 메트릭 조회
- 각 HPA 정의에 설정된 메트릭 기준에 따라 리소스 사용량(resource utilization)을 조회한다.
- 타겟 워크로드 조회
- HPA의 scaleTargetRef에 정의된 워크로드 리소스를 찾고,
- 해당 리소스의 .spec.selector 레이블을 기준으로 타겟 파드 목록을 선정한다.
- 메트릭 수집
- 리소스 메트릭 (CPU, memory 등): resource metrics API에서 파드 단위 메트릭을 가져온다.
- 커스텀 메트릭: custom metrics API에서 가져온다.
- 오브젝트/외부 메트릭: 해당 오브젝트를 설명하는 단일 메트릭을 가져온다.
리소스 메트릭 처리 방식
CPU처럼 per-pod 리소스 메트릭을 사용할 경우, 다음 방식으로 작동한다.
- 각 파드의 컨테이너가 설정한 리소스 요청량(request) 기준으로, 현재 사용량 대비 비율을 계산한다.
- 목표값이 비율(target utilization)이면, 각 파드의 CPU 사용률을 퍼센트로 계산한다.
- 목표값이 절대값(target raw value)이면, 실제 메트릭 값을 직접 사용한다.
- 이후, 모든 파드의 평균값을 구한 뒤, 이를 기반으로 레플리카 수 조정 비율을 산출한다.
만약 어떤 파드의 컨테이너가 리소스 요청값을 설정하지 않았다면, 해당 파드의 CPU 사용률은 정의되지 않으며 HPA는 해당 메트릭을 기반으로 스케일링을 하지 않는다.
커스텀 및 외부 메트릭 처리 방식
- Per-pod 커스텀 메트릭
- 각 파드별로 수집된 메트릭 값을 개별적으로 비교하여 스케일링 판단을 함.
- 예: 파드마다 QPS(초당 요청 수)를 측정하고, 파드당 QPS가 일정 수치를 초과하면 스케일 아웃.
- → 리소스 메트릭처럼 작동하지만, CPU 사용률처럼 "비율" 계산이 아닌 절대값 기준으로 비교함.
- 오브젝트 메트릭 / 외부 메트릭
- 전체 시스템에서 단일 메트릭 값을 기준으로 스케일 판단함.
- 예: SQS 대기 메시지 수, 외부 API 호출 수 등.
- → 이 단일 값을 원하는 목표값(target value)과 비교하여 적정 파드 수를 계산함.
- → autoscaling/v2 API에서는 이 값을 파드 수로 나눈 값을 활용해 per-pod처럼 비교할 수도 있음.
메트릭 API와 Metrics Server
컨트롤러는 HorizontalPodAutoscaler에 지정된 메트릭에 대한 타겟 파드의 리소스 사용률을 조회해야 한다. 이 메트릭은 컨트롤러가 접근할 수 있어야 하며, 쿠버네티스에서는 이를 위해 다음 세 가지 API를 사용한다.
- metrics.k8s.io
- custom.metrics.k8s.io
- external.metrics.k8s.io
즉, 이 세 가지 API가 클러스터에서 사용 가능해야 HPA 기능을 정상적으로 사용할 수 있다. 기본적으로 쿠버네티스 클러스터에는 이 API들이 기본 제공되지 않기 때문에, 클러스터에서 지원하는 API 리소스를 확인해야 한다. 확인 방법은 다음 명령어를 사용한다.
$ kubectl api-resources
# metrics가 포함된 API Resources 필터링
$ kubectl api-resources | grep metrics위의 API는 애드온에 의해 제공되며, 별도로 애드온을 설치해야 한다. 가장 간단하게는 Metrics Server를 설치하면 해당 API Resource를 사용할 수 있게 된다. 아래의 명령어를 통해 간단히 설치할 수 있다.
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml만약 metrics-server 설치 시 아래 에러가 발생한다면 deployment에 arguments를 하나 추가해야 한다.
E0104 09:04:26.156491 1 scraper.go:149] "Failed to scrape node" err="Get \"https://192.168.35.167:10250/metrics/resource\": tls: failed to verify certificate: x509: cannot validate certificate for 192.168.35.167 because it doesn't contain any IP SANs" node="k8s-cp1"
E0104 09:04:26.159954 1 scraper.go:149] "Failed to scrape node" err="Get \"https://192.168.35.2:10250/metrics/resource\": tls: failed to verify certificate: x509: cannot validate certificate for 192.168.35.2 because it doesn't contain any IP SANs" node="k8s-wn1"
E0104 09:04:26.160729 1 scraper.go:149] "Failed to scrape node" err="Get \"https://192.168.35.183:10250/metrics/resource\": tls: failed to verify certificate: x509: cannot validate certificate for 192.168.35.183 because it doesn't contain any IP SANs" node="k8s-wn2"$ kubectl edit deploy metrics-server -n kube-system
spec:
template:
spec:
containers:
- args:
- ...
- --kubelet-insecure-tls # 이 옵션 추가metrics-server를 성공적으로 설치하였다면 api-resources 항목이 추가될 것이다
$ kubectl api-resources | grep metrics
nodes metrics.k8s.io/v1beta1 false NodeMetrics
pods metrics.k8s.io/v1beta1 true PodMetricsmetrics-server는 metrics.k8s.io API만 제공한다. custom.metrics.k8s.io는 사용자 정의 메트릭으로, 별도의 메트릭 백엔드에 대한 어댑터 서버에서 제공한다. 대표적으로 prometheus-adapter가 있으며, prometheus를 사용하는 경우 이를 통해 커스텀 메트릭을 활용한 HPA도 사용할 수 있다. external.metrics.k8s.io는 외부 메트릭용 API로, 이 또한 메트릭 어댑터 서버가 필요하다. prometheus-adapter가 이 API도 제공한다. 추가적으로 metrics-server가 설치되어 있다면, kubectl top 명령어로 파드와 노드의 리소스 사용량을 확인할 수 있다.
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-cp1 108m 5% 1159Mi 61%
k8s-wn1 32m 1% 1505Mi 39%
k8s-wn2 45m 2% 1590Mi 41%
$ kubectl top pod
NAME CPU(cores) MEMORY(bytes)
todo-api-f75444874-hhzvd 5m 292Miscale 서브리소스
HPA 컨트롤러는 Deployment나 StatefulSet처럼 스케일이 가능한 워크로드 리소스에 접근한다. 이들 리소스는 공통적으로 scale이라는 서브리소스를 제공한다. scale은 다음 기능을 제공하는 API 인터페이스이다.
- 현재 레플리카 수 조회
- 원하는 레플리카 수 설정
서브리소스에 대한 일반적인 설명은 Kubernetes 공식 문서의 API 개념 항목을 참고하면 된다.
HPA 알고리즘 상세 동작 방식
HorizontalPodAutoscaler(HPA)는 현재 메트릭 값과 원하는 메트릭 값의 비율을 기반으로 파드 수를 조정한다. 기본 공식은 다음과 같다
desiredReplicas = ceil(currentReplicas × currentMetricValue / desiredMetricValue)- 현재 메트릭 값이 200m, 목표 값이 100m이면 2배 스케일 아웃 (200 ÷ 100 = 2.0)
- 현재 값이 50m, 목표 값이 100m이면 0.5배 스케일 인 (50 ÷ 100 = 0.5)
단, 이 비율이 1.0에 충분히 가까운 경우(기본 허용 오차는 0.1)에는 아무런 스케일 동작도 수행하지 않는다.

평균 메트릭 계산 방식
targetAverageValue 또는 targetAverageUtilization이 설정된 경우:
- 타겟으로 지정된 모든 파드의 해당 메트릭을 수집하여 평균값을 계산한다.
- 이 평균값이 currentMetricValue로 사용된다.
스케일 판단 전 처리 로직
스케일 조정 전에 컨트롤러는 다음 조건들을 고려하여 일부 파드를 제외한다
- 삭제 중인 파드(DeletionTimestamp가 설정된 파드) 및 실패한 파드
- 메트릭이 누락된 파드: 따로 분리하여 이후 계산에 보수적으로 반영
- 아직 Ready 상태가 아닌 파드
- 초기화 중이거나 비정상 상태인 경우
- 가장 최근의 메트릭이 Ready 이전 시점인 경우
특히 CPU 메트릭 기준 스케일링 시, "Ready 상태 전환"을 정확히 판단하는 데 한계가 있어 아래 설정 값으로 판단한다
- --horizontal-pod-autoscaler-initial-readiness-delay
- 파드가 시작된 후 일정 시간 내에 Ready 상태로 전환된 경우, 아직 완전히 준비되지 않은 것으로 간주한다.
- 이 설정은 Ready와 Unready 상태가 빠르게 전환되는 파드의 초기 불안정 상태를 반영하기 위함
- --horizontal-pod-autoscaler-cpu-initialization-period
- 파드가 Ready 상태가 된 이후에는, 시작 후 해당 시간 내에 발생한 Ready 전환을 최초 Ready 상태로 판단한다.
- 이 기간 동안 파드의 CPU 사용률은 HPA에서 무시되어 초기 과도한 CPU 사용이 스케일링에 영향을 주지 않도록 함
보수적 계산 방식
이후의 스케일 비율 계산은 누락된 메트릭과 준비되지 않은 파드를 보수적으로 처리한 후 다시 수행한다
- 스케일 인 시: 메트릭이 없는 파드는 100% 사용 중인 것으로 간주
- 스케일 아웃 시: 메트릭이 없는 파드는 0% 사용 중인 것으로 간주
준비되지 않은 파드도 마찬가지로 0% 사용 중인 것으로 간주하여 스케일 아웃을 완화한다. 이렇게 보정된 상태에서 다시 사용량 비율을 계산한다. 만약 이 새 비율이 스케일 방향을 반대로 만든다거나, 허용 오차 범위 안에 들어온다면, 스케일링 동작을 수행하지 않는다.
다중 메트릭 처리
HPA에 여러 메트릭이 지정된 경우
- 각 메트릭에 대해 위 공식을 적용하여 desiredReplicas를 산출한다.
- 이 중 가장 큰 desiredReplicas 값을 최종 값으로 사용한다.
단, 어떤 메트릭은 오류로 인해 desiredReplicas 계산이 불가능할 수 있다. 이 경우
- 스케일 업이 필요한 메트릭이 있다면 → 스케일 업 진행
- 스케일 인만 필요한 경우라면 → 스케일 동작 없음
즉, 스케일 업은 진행되지만 스케일 인은 보수적으로 판단하여 생략될 수 있다.
스케일 다운 안정화
스케일 조정 직전, 컨트롤러는 스케일링 추천값(recommendation)을 기록한다. 컨트롤러는 설정된 시간 윈도우 내의 모든 추천값 중 가장 높은 값을 사용한다. 해당 윈도우는 --horizontal-pod-autoscaler-downscale-stabilization 플래그로 설정하며, 기본값은 5분이다.
- 이는 스케일 인을 점진적으로 진행하여 메트릭 값의 급변에 의한 영향을 완화하기 위한 메커니즘이다.
- 만약 HPA가 5분 동안 여러 번 스케일링 추천값을 10, 8, 6 으로 계산했다고 가정해보면, 컨트롤러는 이 중 가장 높은 값인 10을 사용해서 스케일 인을 결정한다.
Pod 준비 상태와 HPA 메트릭 수집
HorizontalPodAutoscaler(HPA)는 파드가 시작될 때의 CPU 사용량을 어떻게 처리할지 제어하는 두 가지 주요 플래그를 제공한다. 이는 HPA가 부정확한 초기 메트릭에 의해 잘못된 스케일 결정을 내리지 않도록 하기 위한 보호 장치다.
- --horizontal-pod-autoscaler-cpu-initialization-period (기본값 5분)
- 파드가 시작된 시점부터 설정된 시간 내에는 해당 파드의 CPU 사용량을 무시한다.
- 단, 아래 조건을 동시에 만족하는 경우는 예외한다.
- 파드가 Ready 상태이고 메트릭 샘플이 전체적으로 Ready 상태 기간에 수집된 경우
- 파드 초기화 중 발생할 수 있는 일시적인 고 CPU 사용량(예: Java 앱 워밍업 등)을 스케일링 판단에서 제외하기 위함이다.
- --horizontal-pod-autoscaler-initial-readiness-delay (기본값 30초)
- 파드가 시작된 직후 일정 시간 동안은, Ready 상태였다가 Unready로 변경된 경우에도 아직 초기화 중인 것으로 간주한다.
- 시작 직후 Ready ↔ Unready 상태를 반복하는 파드를 메트릭 계산에서 제외하여 HPA 판단의 안정성을 확보
- Ready 상태 신호가 충분히 안정적일 때까지 대기
- 파드가 시작된 직후 일정 시간 동안은, Ready 상태였다가 Unready로 변경된 경우에도 아직 초기화 중인 것으로 간주한다.
파드가 Ready 상태이며 지속적으로 Ready를 유지하면, 초기화 지연 기간 내라도 메트릭 계산에 포함될 수 있다. 반대로 Ready 상태를 짧게 거쳤다가 다시 Unready가 되면, 안정적으로 Ready가 될 때까지 메트릭이 무시된다.
Best Practice
초기 부팅 시 CPU 사용량이 높은 워크로드가 있다면 다음과 같이 설정하는 것이 좋다
- startupProbe 사용: 초기 CPU 사용량이 지나간 후에만 헬스체크가 통과되도록 구성
- readinessProbe 조정: CPU 스파이크가 끝난 뒤에만 Ready로 간주되도록 initialDelaySeconds 등을 적절히 설정
- --horizontal-pod-autoscaler-cpu-initialization-period 값 조정을 통해 실제 앱의 초기화 시간이 긴 경우 이 값을 늘려서 해당 기간의 CPU 메트릭을 무시하도록 설정
워크로드 스케일 안정성
HPA는 메트릭이 동적으로 변하기 때문에 복제본 수가 자주 오르내리는 현상이 발생할 수 있다. 이를 스케일링 스래싱(thrashing) 또는 플래핑(flapping)이라고 부르며, 사이버네틱스의 히스테리시스(hysteresis) 개념과 유사하다.
롤링 업데이트와 오토스케일링
- Deployment에 대해 롤링 업데이트를 수행할 때, Deployment 컨트롤러는 기본 ReplicaSet을 관리한다.
- HPA는 하나의 Deployment에 바인딩되어 Deployment의 replicas 필드를 관리한다.
- Deployment 컨트롤러는 롤아웃 시 및 롤아웃 후에 하위 ReplicaSet들의 레플리카 수가 적절히 합산되도록 조절한다.
- StatefulSet의 경우, 롤링 업데이트 시 HPA가 적용된 레플리카 수를 직접 관리하며, ReplicaSet과 같은 중간 리소스는 존재하지 않는다.
리소스 메트릭 기반 스케일링 지원
모든 HPA 대상 워크로드는 해당 파드의 리소스 사용량(예: CPU, 메모리)을 기반으로 스케일링 가능하다. 파드 스펙 정의 시 반드시 resource requests (cpu, memory 등)를 명시해야 한다. 이 요청량을 기준으로 실제 사용량과 비교하여 HPA 컨트롤러가 스케일 업/다운 여부를 판단한다.
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60위 설정은 파드들의 CPU 평균 사용률이 60%가 되도록 스케일링 한다는 의미다. 사용률은 현재 사용량 / 요청한 리소스량의 비율이다.
모든 컨테이너의 리소스 사용량을 합산하기 때문에, 특정 컨테이너가 과도하게 사용해도 전체 파드 사용량이 기준 이하일 경우 스케일 아웃이 안 될 수 있다.
컨테이너 단위 리소스 메트릭 지원 (Kubernetes v1.30부터 안정화)
HPA는 파드 내 특정 컨테이너별 리소스 사용량을 기준으로 스케일링할 수도 있다. 예를 들어, 웹 애플리케이션 컨테이너만 기준으로 스케일링하고, 로깅 사이드카 컨테이너는 무시할 수 있다.
type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60이 경우, 모든 파드의 application 컨테이너 CPU 평균 사용률이 60%가 되도록 조정한다.
컨테이너 이름 변경 시 주의사항
- HPA가 추적하는 컨테이너 이름을 변경할 때는 순서대로 진행해야 한다.
- 먼저 워크로드 리소스(예: Deployment) 업데이트 전에 HPA 설정을 수정해 이전 이름과 새 이름을 동시에 추적하도록 한다.
- 이렇게 하면 변경 중에도 스케일링이 정상적으로 작동한다.
- 변경 완료 후에는 이전 컨테이너 이름을 HPA 설정에서 제거한다.
커스텀 메트릭 기반 스케일링
- Kubernetes v1.23부터 안정화되었으며, 이전에는 autoscaling/v2beta2 API 버전에서 베타 기능으로 제공됨.
- autoscaling/v2 API 버전을 사용하면 Kubernetes에 기본 내장되지 않은 커스텀 메트릭을 기반으로 HPA를 설정할 수 있다.
- HPA 컨트롤러는 Kubernetes API를 통해 커스텀 메트릭을 조회한다.
다중 메트릭 기반 스케일링
- 역시 v1.23부터 안정화됨.
- autoscaling/v2 API 버전을 사용하면 여러 메트릭을 지정할 수 있으며, 각 메트릭에 대해 스케일링 권장치를 계산한다.
- 최종 스케일은 각 메트릭별 권장 스케일 중 가장 큰 값을 선택하며, 최대값을 초과하지 않는다.
메트릭 API 지원
HPA 컨트롤러가 메트릭을 가져오기 위해서는 클러스터 관리자가 다음을 보장해야 한다:
- API 집계 레이어가 활성화되어 있어야 한다.
- 필요한 API가 등록되어 있어야 한다:
- 리소스 메트릭: metrics.k8s.io API (Metrics Server가 일반적으로 제공하며 클러스터 애드온으로 실행)
- 커스텀 메트릭: custom.metrics.k8s.io API (서드파티 메트릭 어댑터 제공)
- 외부 메트릭: external.metrics.k8s.io API (위 어댑터가 제공 가능)
스케일링 동작 설정
- autoscaling/v2 API 사용 시 behavior 필드를 통해 스케일 업과 스케일 다운 동작을 각각 설정할 수 있다.
- scaleUp, scaleDown 아래에 개별 동작 정책을 정의한다.
스케일링 정책 (Scaling Policies)
behavior의 policies에 하나 이상의 정책을 설정할 수 있다. 정책은 파드 수(Pods) 또는 비율(Percent) 단위로 최대 변경량을 제한한다.
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60- periodSeconds는 정책이 적용되는 기간(최대 1800초)이다.
- 위 예시에서는 60초 동안 최대 4개 파드 또는 현재 파드의 10% 중 더 큰 값만큼 스케일 다운 가능하다.
- 예를 들어, 파드 수가 40개 이하일 때는 4개 제한 정책, 40개 초과일 때는 10% 제한 정책이 적용된다.
- selectPolicy 필드를 사용하면 스케일링 정책 선택 기준을 변경할 수 있다. 예를 들어,
- Min: 여러 정책 중에서 가장 적은(작은) 변경량을 허용하는 정책을 선택한다.
- Disabled: 해당 방향(스케일 업 또는 스케일 다운)에 대한 자동 스케일링을 완전히 비활성화한다.
behavior:
scaleDown:
selectPolicy: Disabled안정화 윈도우 (Stabilization Window)
메트릭 변동으로 인한 잦은 스케일링 변경(플래핑)을 줄이기 위해 사용된다.
behavior:
scaleDown:
stabilizationWindowSeconds: 300- 최근 5분 간의 권장 상태 중 가장 큰 값을 참고해 스케일 다운을 제한한다.
- 이로 인해 파드를 잦은 삭제/생성 반복하는 것을 방지한다.
- scaleUp.stabilizationWindowSeconds : 스케일업 시에는 최근 일정 시간 동안의 추천값 중 가장 낮은 값을 사용
- scaleDown.stabilizationWindowSeconds : 스케일다운 시에는 최근 일정 시간 동안의 추천값 중 가장 높은 값을 사용
허용 오차 (Tolerance)
- Kubernetes v1.33부터 알파 기능으로 도입, 기본 비활성화 상태
- 메트릭 변화가 설정된 허용 오차 이내일 경우 스케일링을 무시한다.
- 예시 (메모리 목표 100MiB, 스케일 업 허용 오차 5%):
behavior:
scaleUp:
tolerance: 0.05 # 5% tolerance for scale up- 메모리 사용량이 105MiB 이상일 때만 스케일 업 고려
- 설정하지 않으면 기본 클러스터 전역 허용 오차 10%가 적용됨 (명령행 옵션으로 변경 가능, API로는 불가)
기본 동작 예시
HPA에 behavior를 설정하지 않는 경우에는 다음과 같이 기본동작이 적용된다.
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max- 스케일 다운 시, stabilizationWindowSeconds 기간동안 이전에 계산된 원하는 복제본 수 중 가장 큰 값을 참고한다.
- 스케일 다운 정책은 현재 레플리카 수의 100%까지 제한 없이 제거 가능
- 스케일 업 시 안정화 윈도우 없음, 즉시 확장
- 스케일 업 정책은 15초마다 최대 4개 또는 100% 확장 가능하며, 가장 큰 변경량 선택
kubectl에서 HorizontalPodAutoscaler 지원
- HorizontalPodAutoscaler(HPA)는 모든 API 리소스와 마찬가지로 kubectl에서 표준 방식으로 지원된다.
- kubectl create 명령어로 새 HPA를 생성할 수 있다.
- kubectl get hpa로 HPA 목록 조회, kubectl describe hpa로 상세 정보 확인 가능하다.
- kubectl delete hpa로 HPA를 삭제할 수 있다.
- 특별히 kubectl autoscale 명령어가 있는데, 이를 통해 HPA 오브젝트를 간단히 생성할 수 있다.
- 예를 들어,는 ReplicaSet foo에 대해 CPU 사용률 80%를 목표로, 복제본 수를 2~5개 사이로 자동 조절하는 HPA를 생성한다.
kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80
암묵적 유지 관리 모드 비활성화
- HPA 구성을 변경하지 않고도 특정 대상의 HPA를 암묵적으로 비활성화할 수 있다.
- 대상의 원하는 레플리카 수가 0으로 설정되고 HPA의 최소 레플리카 수가 0보다 클 경우, HPA는 대상 스케일 조정을 중단한다.
- 이때 HPA는 자신의 ScalingActive 조건을 false로 설정한다.
- 다시 활성화하려면 대상의 원하는 레플리카 수나 HPA의 최소 레플리카 수를 수동으로 변경하면 된다.
Deployment와 StatefulSet의 HPA 마이그레이션
- HPA 활성화 시 Deployment와 StatefulSet 매니페스트에서 spec.replicas 필드를 제거하는 것이 권장된다.
- 제거하지 않으면 kubectl apply -f deployment.yaml 등으로 리소스 변경 시, Kubernetes가 항상 spec.replicas 값에 맞춰 파드 수를 조정하려고 한다. 이는 HPA와 충돌하여 잦은 스케일링 변동(thrashing, flapping)을 유발할 수 있다.
- 단, spec.replicas 제거 시 기본값이 1이기 때문에, 최초 한 번 파드 수가 줄어드는 현상이 발생할 수 있다.
- 변경 후에는 정상적으로 롤링 업데이트가 작동한다.
- 파드 수 감소를 방지하려면 다음 방법 중 하나를 사용한다.
- Client Side Apply (기본 방식)
- Server Side Apply
- Client Side Apply에서 kubectl apply edit-last-applied deployment/<deployment_name> 명령어로 편집기 열기
- 편집기에서 spec.replicas 삭제 후 저장 및 종료
- 이 시점에서는 파드 수 변경 없이 업데이트가 적용된다.
- 이후 매니페스트 파일에서도 spec.replicas를 삭제하고 소스 관리 시스템에 반영한다.
- 이후부터는 kubectl apply -f deployment.yaml로 계속 작업 가능하다.
시나리오 예제 (부하 테스트 수행)
Kubernetes HPA (파드 오토스케일링) [1] - 기초
HPA (Horizontal Pod Autoscaler)는 Deployment나 StatefulSet 등의 워크로드의 레플리카 갯수를 수요에 맞게 자동으로 스케일링하도록 한다. 수평 스케일링은 레플리카를 늘리고 줄이는 것을 의미한다. 통상
beer1.tistory.com
Kubernetes HPA (파드 오토스케일링) [2] - 동작 제어
이전 장에서는 HorizontalPodAutoscaler에 대한 기본적인 내용에 대해 알아보았다. HorizontalPodAutoscaler에 대해 처음 들어보았다면 아래 글을 먼저 읽어보는 것이 좋다. 2025.01.05 - [DevOps/Kubernetes] - Kubernet
beer1.tistory.com
'Kubernetes & EKS > k8s 공부 기록' 카테고리의 다른 글
| [kubernetes] IP/ENI 예비 할당 정책 (0) | 2025.06.24 |
|---|---|
| [kubernetes] Network Policy 02 (0) | 2025.06.03 |
| [kubernetes] Network Policy 01 (0) | 2025.06.03 |
| [kubernetes] API Groups (0) | 2025.06.03 |
| [kubernetes] 파드 자원관리 (Quality of Service, QOS) (0) | 2025.05.18 |